There are local elections on Thursday 2 May, which is an ideal opportunity to reach net zero Tories on Eastleigh Borough Council! The good news is that there is only one Tory left on the council, so there’s an excellent chance of reaching net zero!
The bad news is that tactical voting isn’t always popular and other parties are parroting Tory misinformation, so there’s also a realistic chance of missing out on reaching net zero. I get it, tactical voting is horrible, especially if you’re one of the many great candidates that are not recommended by tactical voting sites. Unfortunately, without reforming our first past the post voting system, tactical voting is one of the few options to avoid the worst candidates being elected.
Tactical voting is also a blunt instrument, so it doesn’t take into account local issues, like the Lib Dems currently having an unhealthy majority on the local council. I would personally like to see far more independent councillors, and a better mix of parties represented on the council, but the biggest threat to Eastleigh is still the Conservative government loyally propped up by Eastleigh’s Conservative MP. Claiming that the local Green/Labour/Lib Dem (delete as appropriate) party are as bad or worse than the national Tory party is just not credible.
It’s worth repeating that not all parties, and not all politicians are the same. No party is perfect, and there are good and bad politicians in most parties. (Yes, even in the Conservative party.) If you’re not comfortable with tactical voting, take some time to check out who’s standing in Eastleigh before Thursday but make sure anyone you consider voting for is working extremely hard for your vote. It takes a huge amount of effort to get elected and a paper candidate is never going to beat a Tory.
Whatever you do, vote on Thursday! Just not for a Tory!
Just like Johnny Mercer, Paul is always keen to be held to account in his role as Eastleigh’s MP, so I must start this annual review with an apology for skipping his 2021/22 review. While I’m sure we’d all rather forget Truss-Kwarteng and their I Can’t Believe It’s Not A Budget, I still hope to fill in the gaps but there’s an election coming so it only seems fair to focus on Paul’s more recent work.
Rishi Sunak’s five Conservative party pledges
Paul’s most important contribution to politics is his line on the Tory whip’s spreadsheet and he has once again maintained his impeccable track record of voting exactly how he was told to. Even so, with Rishi “integrity, professionalism and accountability” Sunak in charge, toeing the party line was going to be easier than ever for Paul “integrity and honesty” Holmes this year.
1. Halve Inflation: understandably reluctant to take any responsibility for rising inflation (wars, climate change, trade barriers, special financial operations, etc.) but only too happy to take credit for falling inflation. Food inflation is still going to make cooking a meal for 31.17p pretty tricky though.
“To then say to them, actually we’re going to bring down inflation when they blame us for inflation rising in the first place, that makes it really difficult.”
Unfortunately Paul only blames Liz Truss for the dire position the party finds itself in, perhaps forgetting the country is also in a dire position thanks to him and his party putting Liz Truss in power in the first place. Party first as always.
2. Grow the Economy: we’re currently heading for a recession but with Paul’s plan to save our high street, and Sunak’s world-beating idea to use legislation to redefine reality, I’m sure we’ll be fine.
3. Reduce Debt: Paul is always keen to distract attention towards Eastleigh Councils debt, although strangely without any context whatsoever. Despite all Paul’s bluster, the Chartered Institute of Public Finance and Accountancy review of Eastleigh Borough Council’s debt found,
“The council appears to understand the challenges its indebtedness position creates and has clear strategies and mitigations for managing them. EBC’s investment portfolio has a clear strategic purpose.”
CIPFA report
Perhaps Jeremy Hunt could get some tips from Eastleigh Council on prudent financial management before spaffing any uncosted tax giveaways on Conservative donors in a desperate attempt to buy the next election.
4. Cut NHS Waiting Lists: well I think we can all agree that the 40 new hospitals and the government’s skillful handling of NHS strikes has made a huge difference to waiting lists.
5. Stop Small Boats: this is Paul’s chance to shine, having been Priti Patel’s PPS at the start of the government’s wildly successful campaign to stop anyone claiming asylum in the UK. Unfortunately it actually turns out to be the low point of his Westminster career.
On the anniversary of the 2019 general election, in the Safety of Rwanda (Asylum and Immigration) Bill debate where MPs were discussing legislation that seeks to alter reality in a desperate attempt to continue the Tory government’s ridiculous obsesion with deporting money to Rwanda, Paul interrupted the shadow home secretary to ask what Labour’s plan was.
Ian Dunt was impressed by this line of questioning…
“Cooper is asked what Labour’s plan is. Starmer was asked the same thing on Radio 4 this morning, persistently. There are many things to criticise Labour for, but this isn’t one of them and indeed the question betrays one of the intellectual failings of Westminster.”
Ian Dunt, Twitter/X, 12th December 2023
It gets worse. Having dutifully delivered the line he was very likely given, he seemed to get carried away and finished by claiming “everything that [the shadow home secretary] says she would do, this government is already doing” which is very clearly false.
There may be some unobservant back benchers who could have missed the obvious differences between Labour’s plans and the inhumane and ineffective pantomime that the Conservative government persists with but Paul was Patel’s PPS when she was home secretary, so I am quite sure he knows better.
As far as I can tell Paul has not apologised or corrected the record, so it’s difficult not to conclude that Paul is a liar.
King’s Speech
“It is a privilege to speak in this debate on the King’s Speech, because I genuinely believe that crime and sentencing is one of this Government’s key successes in the past 13 years.”
For the gory details of the government’s “success”, I would definitely recommend reading the Secret Barrister’s, Stories of the Law and How It’s Broken.
One Horton Heath: Paul hasn’t given up on his failed attempts to stop the One Horton Heath project, finishing the year with another of his signature contributions to Prime Minister’s Questions complaining about Eastleigh Council’s house building.
“Eastleigh Borough Council recently refinanced its failed One Heaton Heath housing project to the tune of £148 million, with no houses built and interest payments of £386,000 per month.”
Oddly Paul doesn’t seem to have anything to say about the nearby Uplands Development. It’s a stone’s throw from One Horton Heath and is also a failure by Paul’s definition, with £ millions spent on infrastructure (a road and a school) but no houses yet. Perhaps I just missed Paul’s campaign on this one, or maybe there’s some reason he doesn’t complain about it. 🤔
M27 resurfacing: if I had a VIP PPE contract for every time Paul announced the M27 was about to be resurfaced, I would be sitting on a yacht by now!
Will the work start while Paul is still Eastleigh’s MP? He’s running out of time.
Southampton Airport expansion: Paul got a spectacular photo opportunity opening the airport extension this year. In a climate crisis. Excellent work.
To be fair to Paul, his contribution to the runway extension was likely very similar to his contribution to lowering inflation, or the M27 resurfacing for that matter.
Hamble Airfield Quarry: Paul’s latest campaign is absolutely perfect for any MP:— who would want a gravel pit next to their house? Or next to a school! Paul has firmly attached himself to local opposition to the quarry and even introduced his second (doomed) 10 minute rule bill in parliament!
I would agree that planning rules are inadequate for any applications with large health and environmental implications, as demonstrated by the Southampton airport extension. Paul’s Planning (Quarries) Bill isn’t going to fix that though.
Drake Hotline Bling Meme comparing noise and pollution from a quarry with noise and pollution from an airport extension
Even if the government supported Paul’s Planning (Quarries) Bill (lol), there’s unlikely to be time left for it to progress, so it’ll go the way of most 10 minute rule bills. My guess is that the quarry will eventually go ahead but that Paul will get through the next general election before the Conservative Hampshire County Council make a decision.
Sewage: just kidding, this is obviously not something Paul has waded in to!
Hedge End station accessibility: more talk and photo ops but no progress. I’m sure he’ll continue the fight to jump the station accessibility funding queue if we elect him to the new Hamble Valley constituency. (Spoiler alert for the missing annual review: this isn’t his first station accessibility campaign!)
Constituents
Paul’s MO on social media has long been insulting and blocking constituents to shut down debate, and this year was no different. Hilariously, and with no sign of any self-awareness, he recently complained about being blocked by someone else! 🤣
“Sorry Christine I’m blocked by Liz as she hates debate and doesn’t like standing up against her party and their disastrous local record.”
Paul Holmes, Twitter/X, 12th December 2023
Liz Jarvis is the Lib Dem parliamentary candidate for Eastleigh and while I would personally rather politicians didn’t block people, I can understand why someone would choose to block Paul based on his fairly unpleasant use of social media. Paul will be campaigning for the new Hamble Valley constituency in the upcoming general election, not Eastleigh, so I’m not entirely sure why he appears to be so threatened by her. Perhaps because she does actually stand up against her local party, disagreeing with them on the airport extension and Solent freeport …according to Paul Holmes. 🤦♂️
When I asked what people wanted to know in an annual review, the most common requests were for attendance in parliament, votes, number of local surgeries, number of cases handled etc. Unfortunately MPs are not obliged to publish any information at all as far as I can tell but there are some clues.
Paul has a government job (currently PPS to Michael Gove after stepping down as Conservative Vice Chairman earlier in the year) so he has more incentive than a normal backbench MP to attend parliament and vote how he’s told to and, as his parliamentary page shows, Paul does turn up, vote, and deliver the government’s lines to take.
“He won it because he was as given it after mims stepped down for a safer one. I was literally in the room for the conversations”
Ems Barr, Twitter/X, 22nd October 2023
There are no publicly verifiable records of how many constituents contact Paul, or what the end result is, but Pauĺ claims to work very hard and while not everyone is happy, he continues to get generally favourable reviews.
“You are just deluded. 20000 cases all completed on time and a strong team. As I said before I can’t wait until I no longer represent you. Such an unpleasant man.”
Paul Holmes, Twitter/X, 29th December 2023
It’s not clear whether that’s 20,000 cases this year or since he was elected, and from a previous review around 5% are about pot holes, but Paul’s strong team includes the very pleasant Daniel Sydenham.
Paul suspended his senior parliamentary assistant to conduct an investigation after reports surfaced that Daniel featured in a Halloween video dressed as Jimmy Savile. That’s in stark contrast to Paul’s usual preference for keeping the accused in their job while waiting for a completed report before expressing any views. Maybe that’s just his approach for Conservative leaders though. Either way, I haven’t seen any outcome of the investigation and Daniel’s LinkedIn profile still shows him as Paul’s senior assistant.
If you have a problem… if no one else can help… and if you can find him at his out of town Conservative club office, or one of his sporadic street surgeries… maybe you can ask for Paul’s help. Paul’s next job could be in Citizens Advice, he just doesn’t know it yet.
Conclusion
I don’t think there were any big surprises this year. We’ve got to know Paul pretty well since 2019 and he’s fairly typical of that New Conservative/Boris Johnson intake of MPs. There’s very likely to be a general election in 2024, so look out for any more inadvertent terminological inexactitudes in the upcoming campaign.
Biggest achievement: securing himself the slightly safer Hamble Valley seat for the next election.
Biggest disappointment: lying in parliament.
And finally, how does Paul feel about how everything is going?
“More and more lately, I have utter despair at coming into work and this party”
As with Paul’s 2020 and 2021 reviews, these are just my personal observations. You may have other examples of times Paul has done well, or things he could do to improve. If you have, please leave a comment below!
A while ago I wrote a CheerLights app for the LaMetric clock, except that you can’t actually really write apps for it,— you just define a sort of catalogue entry for somewhere the clock is going to fetch data from, or in the case of the CheerLights app, the clock gets notified of updates. The actual code needs to run on a server somewhere. Unfortunately the first couple of free cloud compute options I used for running the little app to subscribe to the CheerLights MQTT topic have gone away, and the current server got stopped for not doing enough a while ago!
Fortunately I don’t need to find a new home for the CheerLights server because LaMetric finally implemented an eight year old request to support MQTT, and it actually works very nicely indeed!
Unfortunately it doesn’t look like it’s possible to export, import, or share My Data DIY configuration but to add your own CheerLights app, these are the settings you need.
Type: MQTT Channel
MQTT Config
Host: mqtt.cheerlights.com
Port: 1883
Use TLS: off
Topic: cheerlights
Data Format: Any (JSON or XML)
Frames
Name: CheerLights
Frame Type: Data
Text: {#}
That’s all you should need to display the CheerLights colour names. You can also add different icons that depend on the data received, unfortunately you can only have a maximum of 10 conditional icons which seems really stingy to me. There are, for example, 11 supported CheerLights colours! Fortunately the My Data DIY lets you have one more default icon, which is just enough to cover all 11 CheerLights colours!
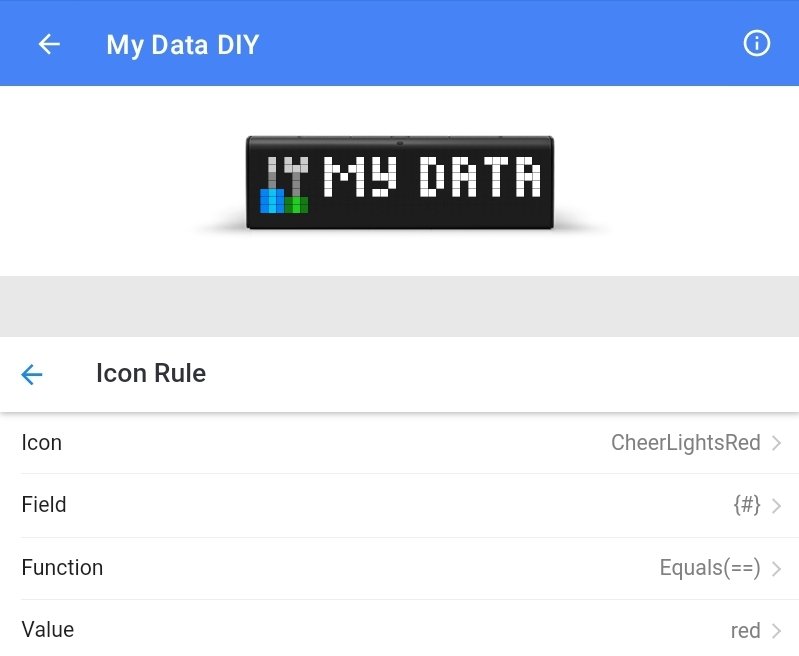
The CheerLightsRed icon rule in My Data DIY
For example, the icon rule for red has these settings.
Now I just need to work out what to with the old app. It’s definitely easier to install instead of all the configuration required for the My Data DIY app, but it needs a new home for the server again. On the other hand, it definitely wouldn’t be worth keeping around if there was a simple way to share My Data DIY settings.
I’m slightly embarrassed about how late this annual review is! It’s been languishing in my drafts for longer than some PMs have lasted in Downing Street! Before getting started, here are just a few reactions to Paul’s previous annual review way back in 2020:
“Biased nonsense.” (Paul Holmes)
“A lot of it’s wrong factually.” (Paul Holmes)
“I’m saying I think you’re wrong to say it’s well researched” (Paul Holmes)
I guess when Paul said, “you can judge me on my record” he meant in a limited and specific way.
Guarantees
Paul was elected to deliver the Conservative party manifesto and his primary role as Eastleigh’s MP is to vote with the government, which he does extremely loyally …even when that breaks his manifesto commitments and Boris Johnson’s guarantees.
I hope no one believes the 40 new hospital lie anymore, but in 2021 Paul also broke the Conservative promise not to raise the rate of income tax, VAT or National Insurance. That’s not all- he broke the pension triple lock promise, and the promise to spend 0.7% of gross national income on international aid as well.
It might be simpler not to bother with a manifesto at the next election.
Having been unhappy about public health restrictions before Christmas, Paul suddenly had strong views about the dangers of delivering leaflets after Christmas. Perhaps it wouldn’t have looked quite so blatantly political in the run up to the local elections if Paul had been at all concerned about genuine risks throughout the pandemic. Like Gavin Williamson sending children back to school for a single day at the height of the unnecessarily deadly Omicron wave.
Other than that, Paul appears to have had relatively little to say on one of the defining events of our age, although he has at least been consistent in urging people to get vaccinated, which is something.
Parliament
It can often seem like Paul is still a local councillor rather than a member of parliament, but this year Paul did something only an MP could: he introduced his own Bill to parliament! Paul is strangely reluctant to use some of the tools available to MPs to highlight important issues but in this case he made use of a Ten Minute Rule Bill to propose changes to the local planning process.
I actually agree with Paul that there is something of a conflict of interest in situations where a local council makes its own planning applications. Unfortunately Paul’s solution appeared to me to make an already opaque process even more opaque and complex. Ten Minute Rule Bills rarely make it as far as an act of Parliament and Paul’s didn’t really stand much chance of success when his government was committed to a policy of “build build build”. Even so, I think this was Paul’s best effort of the year, and better than another Ten Minute Rule Bill which the government did support.
Brexit
Paul was very happy to announce Boris Johnson’s trade deal with the EU on Christmas eve 2020. Frankly it was a bit like panic buying a last minute Christmas present at the petrol station but it was at least better than no deal at all. Even Eastleigh’s local plan got more scrutiny than the Conservative trade deal. Only time will tell whether it’s a good deal or not.
It was a little hard to find the many promised Brexit benefits so soon after Johnson’s skillfully negotiated trade deal but there is one lie that a significant number of people appear to believe: that the UK’s Covid vaccinations could be delivered faster due to Brexit. It is just one of many of Boris Johnson’s lies and I wrote to Paul asking him to uphold the Nolan principles and the Ministerial Code through a vote of no confidence in the Prime Minister.
Unfortunately Paul declined and the vaccination lie started by Johnson lives on even now.
There really isn’t any excuse for further undermining democracy in this way and, given his weak justifications, I get the sense that Paul at least realises he was in the wrong. I am also absolutely sure he would do the same thing again if he was asked.
Despite some frankly bizarre denials, we also learnt that Paul has his own second job. It’s within the rules, and he’s keen to point out that he has not exercised his share options, but it certainly introduces the potential for a conflict of interest in his campaign to reform planning rules. I hope he’s more transparent about it than Owen Paterson was.
Campaigns
Paul has a various local campaigns, so here’s a quick rundown on his progress this year.
One Horton Heath: Paul frequently complains about house building but, other than his failed attempt to change the law, he doesn’t propose any genuine alternatives. Of all his campaigns, this one seems the most likely to fail.
Airport expansion: one of the few things that Paul agrees with the local council about is that the airport should be allowed to extend their runway. In a climate emergency. Paul’s biggest contribution was a petition, which either means he doesn’t understand the planning process, or he doesn’t care. Not ideal for someone who wants to change the planning process.
“Local opposition or support for a proposal is not in itself a ground for refusing or granting planning permission, unless it is founded upon valid material planning reasons”
Paul’s biggest achievement last year was opening a constituency office in the centre of Eastleigh, fulfilling a promise he made to constituents during his election campaign. Sadly his commitment to keeping a town centre office open lasted less than a year. The excuse?
“The company we shared with wanted the space back due to expanding and the other alternatives were too expensive for budgets.”
Paul Holmes
Paul’s use of social media is still problematic. Despite frequently telling people to email him because he doesn’t reply on Twitter, Paul has a tendency to get drawn into unhelpful arguments, where he can be rude to constituents, and even caused something of a pile on to a local councillor. He also falsely accused another constituent of lying. Based on my experience, I doubt he apologised.
Overall, Paul’s record of sharing his views with constituents is patchy. It often takes a lot of pressure before he makes any statement on his website, and there are plenty of issues which he makes no comment on at all. I would love to know what he thinks of the cut to Universal Credit, the murder of Sarah Everard and the Met Police’s response, Priti Patel remaining in post despite breaking the ministerial code, or the bomb joke made by one of his colleagues.
Despite previously being coy about a government career, Paul made it on to the first rung of the ladder this year! His loyalty was rewarded with a job as Priti Patel’s Parliamentary Private Secretary, which was somewhat surprising given he has previously spoken of showing compassion for asylum seekers. It looks like Eastleigh’s constituents will have some competition for Paul’s attention now.
Conclusion
Paul is far from the worst Conservative MP there is but so far he has been too weak to stand up to the lies and corruption which have engulfed his party.
Biggest achievement: first government job as Priti Patel’s Parliamentary Private Secretary. Biggest disappointment: closing his promised constituency office.
As before, these are just my personal observations about Paul’s year as Eastleigh’s MP in 2021. Being so late, I will have definitely forgotten plenty of examples- what do you think Paul did well, and how do you think he could improve?
Now that Twitter is owned by someone who is clearly not a fit and proper person to be running a social media company, I’ve been thinking about what to do.
The most common alternative I’ve seen mentioned is Mastodon, where I already had a dormant account, so this week I thought I’d try a whole day there instead of on Twitter.
The last time I’d tried Mastodon was in 2017 and, well, I didn’t have high hopes. This time was a completely different experience.
Partly that was luck- back in 2017 I had picked a server run by James Smith and it’s still going strong, so there was already a community and people I recognised, and I didn’t have to think about where to create an account.
I think it was also partly the kind of people I follow on Twitter- a lot of them had recently created Mastodon accounts I could find and follow. Although it was also great to find people I haven’t seen on Twitter before, having some familiar faces was nice.
Overall it really did remind me of when I first joined Twitter. Back then I tried to keep the number of people I followed to a nice manageable 80… which I appear to have reached already on Mastodon! Oh well!
I’ll definitely be back for another Mastodon Monday so please say hi if you’re trying it out as well!
Earlier this month Nicholas Arnold, Margaret Atkinson, Mark Banks, Ben Burcombe-Filer, James Charity, Adrian Cooper, Lisa Crosher, James Foulds, Jeanette Fox, Danny Francis, Jerry Hall, Susan Hall, Patti Hayes, Joy Haythorne, Mike Hughes, Shelagh Lee, Daniel Newcombe, Simon Payne, Gary Phillips, Joan Raistrick, Paul Redding, Albie Slawson, Roger Vivian, Alan Weatherall, and Chris Yates stood as Conservative candidates in the Eastleigh local elections.
As far as I know, only one of them has called for the Prime Minister to go for the Downing Street pandemic parties, and clearly none of them were concerned enough about Johnson’s behaviour to stand as independent candidates.
Eastleigh’s MP, Paul Holmes, a vocal supporter of the Prime Minister, even hosted a campaign visit to Southampton Airport, where Johnson lied about the tax free area only being possible due to leaving the EU.
If none of them had the integrity to challenge their leader’s behaviour when it so clearly breaches the standards expected in public life, how could anyone trust them on local issues? The election results suggest voters didn’t trust them.
Paul in particular has seemed more interested in putting his career, and party leader first, despite the damage being done to his party and the country.
“I understand your concerns about recent distractions from the good work the Government has been trying to do. I am disappointed that certain mistakes have damaged people’s confidence in our ability to deliver on the really important issues which affect all our daily lives.”
He could have done something about the distractions long ago, but chose not to.
“As you will know, the Prime Minister, his wife, and the Chancellor have been fined by the police for breaching lockdown rules by attending a gathering to celebrate his birthday. Like you, I was deeply concerned to read this news, and I will follow further developments closely.”
“You may be aware that the House of Commons recently agreed to refer the Prime Minister to the Committee of Privileges to investigate whether he had knowingly misled Parliament. This motion passed without a vote, which means an investigation will now be carried out.”
“As I have said previously, I believe it is vital that people around the country continue to have faith that those in power in our democratic system are held to account, and that they meet the high standards expected of those who hold public office. I would therefore have voted for this investigation if it had come to a vote.”
Wait until Paul finds out that the Prime Minister is changing the rules to thwart parliamentary standards again, just like he did with Owen Paterson!
“However, I remain of the view that all the processes that are underway must be allowed to run their course. The Sue Gray report has not been published and the Metropolitan Police investigation has not concluded.”
On the plus side, I am pleasantly surprised that Paul hasn’t followed the example of some Conservative MPs and told us all to move on. He has also resigned from his government position, which should allow him to start holding the government, and the Prime Minister to account…
…except he hasn’t yet. Oddly there isn’t actually any criticism of the Prime Minister in Paul’s statement, and no indication that he thinks Johnson should resign.
“It is distressing to me that this work on your behalf has been tarnished by the toxic culture that seemed to have permeated Number 10.”
It’s as if Number 10 was just ambushed by the toxic culture.
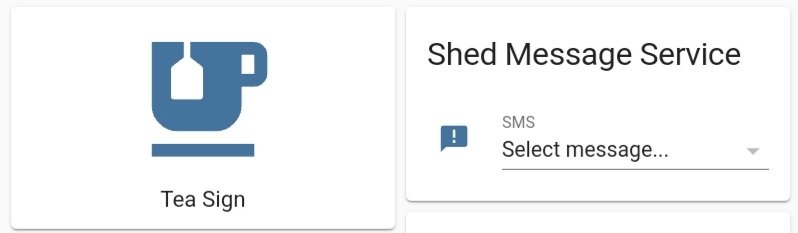
I’ve been shed working for a few months now and while being away from distractions is a big plus, sometimes you want a distraction. Especially when the distraction is a nice cup of tea!
The first Shed Message System was an old wireless doorbell, which worked but could be somewhat of a surprise on conference calls, so after “accidentally” buying too many Local Bytes smart plugs I upgraded the Shed Message System with an old LED light box. No more loud ringing!
Obviously the only message was “Tea!” which was good, but what if there was cake instead? I wouldn’t want to be ambushed! So a little bit of Home Assistant hacking later, and I now have a selection of messages using an input select helper.
Turning the smart plug (LED sign) on with the big tea button automatically sets the dropdown to “Tea!” (the original and still the best) and turning it off resets the dropdown. So now I just have to check Home Assistant when the sign lights up to get the message and, even more amazingly, someone in the house is daft/lovely enough to make tea and use the Shed Message System!
At long last Paul Holmes has made a statement in relation to lockdown parties in Downing Street, after reports first emerged towards the end of last year.
“The Prime Minister will be aware that Eastleigh was formed as a railway town and, from producing locomotives and carriages to building gliders for the D-day landings, Eastleigh has a proud railway heritage. Given that pedigree, its excellent transport links and the need to level up the south, does he agree that Eastleigh would make the perfect home for the new headquarters of Great British Railways?”
You might be wondering what that has to do with his views on government parties during the pandemic. The only relevance is that this was Paul’s contribution during Prime Minister’s Questions today, which was dominated by Boris Johnson’s admission that he had in fact attended one of the parties during lockdown after all.
Paul claims that he was merely trying to secure money, jobs and investment for Eastleigh. Even if you believe that he wasn’t just providing friendly cover for the Prime Minister during a difficult PMQs, Paul appears to be appealing to the Prime Minister to influence the new railway headquarters decision when there is meant to be some sort of competition for towns to submit bids. That’s an interesting approach on the day that the government’s VIP lane for PPE contracts was found to be unlawful.
“I did notice, however, that I still have not received a Christmas card from him—[Interruption.] which is shocking. No doubt—I ask him to comment—that is an indication of my standing in his little black book in the Whips Office.”
I don’t think Paul need worry about his standing with the whips after today!
Anyway, I assume Paul will eventually stop ignoring the issue and actually make a statement. I’ll add a link, or the text, here when he does.
“I know many constituents have contacted me about the recent revelations regarding events in Downing Street.
First and foremost, I want to make it clear that I have not attended any parties in Downing Street myself.”
It’s telling that he starts by clarifying that he wasn’t at the parties. He knows it was wrong.
“The reports we have all seen in the news are deeply disappointing. Not only do I understand your anger and frustration about the reported parties in Downing Street, I share that anger and frustration.”
The Prime Minister said he understood the anger back in December last year: “May I begin by saying that I understand and share the anger up and down the country at seeing No. 10 staff seeming to make light of lockdown measures?” We had to wait a very long time to hear something similar from Paul.
“These reports raise serious questions about the conduct of people working in Downing Street and like you, I want answers to these questions. I believe Sue Gray’s report will address these points. While I welcome the Prime Minister’s apology, I also believe he needs to address these concerns.”
Paul seems to be playing his part in Operation Save Big Dog already, deflecting blame from the Prime Minister to “people working in Downing Street”. Classy.
While I welcome Paul’s statement, it’s too little too late.
“Fundamentally, there is no excuse for those who make the rules, to break the rules. Those found to be doing so should be disciplined and face the consequences, with no exceptions.”
Well Paul, over to you. Or did you mean no exceptions except for the Conservative Prime Minister?
Update: Paul’s update!
Paul has updated his email template since Sue Gray’s update.
“I appreciate and understand the ongoing anger and frustration around these matters, and I remain clear that anyone found to have broken the rules must face the consequences of their actions.”
It’s already clear that the Prime Minister repeatedly breaks the ministerial code, and has done so since before it was revealed that he broke his own lockdown law. It’s also clear that Paul isn’t interested in those rules, and doesn’t expect the Prime Minister to face any consequences.
Worse, Johnson appears to be lying in Parliament even more regularly than usual in a desperate attempt to cling on to power, and has now even sunk to repeating far-right conspiracies to score political points.
“I have said that I will make a further statement when Sue Gray’s report is published. Given the concurrent police investigation, it has not yet been possible for her to release her full report, which is why only a limited update has been published so far. I look forward to the full report in due course, as well as the outcome of the police investigation, and I will make a further statement then as promised.”
Instead of distancing himself from even the worst of the Prime Minister’s false allegations, Paul is still content to stick to Johnson’s “wait for the report/wait for the police investigation” script.
It’s worth reading Sue Gray’s limited update. The full report should be interesting if the Prime Minister actually ever publishes it.
“I understand that many are calling for decisions to be taken now, but I have always been of the view that the full facts must be known in a case before a judgement can be made. However, I want to assure you that I continue to take this matter extremely seriously as your MP, and that I have heard and taken on board your views and have made them clear to the Prime Minister and Number 10.”
The facts are that Boris Johnson is a liar, and Paul Holmes still has confidence in him.
“I fully support the Prime Minister. He’s getting on with the job.”
“I have every confidence that he will be able to deliver going into the next election.”
His enthusiastic support was somewhat unexpected after he had initially claimed he was angry, but said that we should wait for the result of the police investigation.
“I do not support the lobbying activities that Owen Paterson undertook while working as an MP for two companies that he acts as a paid consultant for. This is expressly forbidden in the rules and it is right that he is punished.”
I think most people agree. I also think most MPs agree. I’m fairly certain most Conservative MPs, like Paul, would now publicly claim they agree as well.
I’m inclined to believe them, which makes it even more inexcusable that they allowed the motion to suspended Owen Paterson, who had been found guilty of corruption, for 30 days to be hijacked by the government.
Instead of passing the motion to suspended Owen Paterson, the motion was amended to politicise the standards process. Conservative MPs were told to support the amendment, whether they liked it or not, and the amendment passed.
“I did not vote for the ‘Leadsom Amendment’ which would have stopped Owen Paterson being punished”
Paul has a government job as PPS to Priti Patel. Angela Richardson lost a similar job for defying the government whip but, as far as I know, Paul did not lose his job. The most likely explanation is that he did not rebel; he just didn’t vote for some reason that was acceptable to the government.
“I did vote for a review into the Standards Regime which was encompassed in the second vote.”
“I am pleased that the Government has now changed its mind and is proceeding with a review into the standards regime but in a more cross-party and collaborative way.”
I hope the review will look at why ministers like Priti Patel can break the rules and escape without punishment
The review also needs to examine the Ministerial Code and the conduct of the Prime Minister, as highlighted by Dawn Brent.
Finally, Paul makes some statements about his own employment…
“For the record, being the Member of Parliament for Eastleigh is the only job that I have and am remunerated for.”
He does also have a job as a PPS in addition to his constituency role, but that is unpaid.
“I do not have a second job and I do not earn any money from any paid consultancies. This is reflected in my own register of interests which is a matter of public record.”
15 hours per month for share options in the “Employment and earnings” section sounds like a second job to me!
He has since revealed more details of his second job on twitter…
“It’s a judging role for a fund to build housing for key workers and NHS workers”
The share options are a £5 discount on the listed share price of £5.50 per share.
Conservative MPs, including Paul, created this scandal themselves, but it’s telling who their anger was reserved for: not the person who broke the rules (Owen Paterson), or the one who tried to rewrite the rules (Boris Johnson).
No, apparently in a WhatsApp message to a group of new Tory MPs, Paul called Chope a “selfish twat” for not allowing the government to make the scandal go away without even a debate in Parliament.
I agree with Theresa May’s remarks in the debate which Chope was so selfish for forcing on Parliament:
“The attempt by honourable and right honourable members of this House, aided and abetted by the Government, under cover of reform of the process, effectively to clear his [Paterson’s] name, was misplaced, ill-judged and just plain wrong.”
“As a new Member of Parliament, Madam Deputy Speaker, I need to ask your advice. Is it acceptable in the House to use the word “liar”, and to accuse a Member of lying?”
He seems more interested in covering for the Prime Minister’s lies than having a debate on improving standards in public life. Ironically Paul seems to have missed the start of the debate where the usual rules that protect the Conservative leader from proper scrutiny had been suspended.
Perhaps he was too busy with one of his other jobs?
On the 14th September Paul Holmes insinuated that GPs in Eastleigh haven’t been working
may I emphasise to the Secretary of State the amount of anger there is in Eastleigh about not being able to get a face-to-face appointment with a GP? He stood at the Dispatch Box and encouraged GPs to get back to work. If necessary, and if that uptake has not happened, will he instruct them to get back to work, so we can at least have face-to-face appointments for my constituents?
He referred to the pandemic easing when he publicised his question on social media, and talks about returning to normal on his website. Unfortunately this complacency, when deaths are still averaging 1,000 per week and cases are rising alarmingly in schools, is likely to prolong Covid related issues getting face-to-face appointments. Surgeries and schools are not getting the investment they need to improve ventilation and control the virus, and the government seem to have all but abandoned proportionate public health measures to keep cases down going in to winter.
Three days after Paul’s question in Parliament, four members of staff were injured in an attack on GP surgery in Manchester. The BMA said,
The narrative that GPs are refusing to see patients face-to-face is dangerous and inaccurate and it has to stop. We call on the health secretary to speak up openly and unequivocally in support of general practice…
Paul hasn’t issued an apology publicly but has apparently said this on an Eastleigh social media group,
Let me make clear from the start that I respect and thank our GPs for the work they do. I am the first to admit that I was called near to last in that statement after two colleagues raised the same issue. I wasn’t expecting to be called and had to quickly speak. It was unwise to say get back to work. I should have said get back to physical appointments more quickly, and I apologise for the implication of the question.
That seems like a pretty weak excuse to me and, while any apology is obviously welcome, it certainly doesn’t go far enough to counter the narrative that GPs are refusing to see patients face-to-face. They are seeing patients, and have been throughout the pandemic. He should be apologising in Parliament and asking the health secretary to condemn the scapegoating of GPs rather than reinforcing the myth that they aren’t working.
It’s also somewhat misleading to just blame the pandemic for the lack of access to GPs. Thanks to the Conservative party, it has been difficult to get appointments for a long time. My own GP practice has had issues and had to merge with other GP practices to survive. While Paul complains about practices merging as if it’s nothing to do with his government, I’d rather they merged than closed completely.
Somewhat strangely for an MP in the ruling party, Paul is apparently campaigning for better access to NHS services. He shouldn’t be campaigning, he should be demanding to know why his government is failing to deliver. The prime minister personally guaranteed 50,000 more GP appointments in the 2019 general election. They would help. Having fuel to get to appointments would also be useful.
Perhaps the 6,000 new doctors are just like the 50,000 new nurses, or the 40 new hospitals. Just another broken promise from Paul and his party. Just keep blaming someone else for the problems.